Editor’s Note: On Mondays we turn the spotlight outside of Porter & Co. to bring you exclusive access to the research, the thinking, and the investment ideas of the analysts who Porter follows.
This month’s spotlight has been focused on the legendary George Gilder, one of Porter’s earliest influences and mentors, and we end this series with a fittingly titled report called Investing in the Climax of the Silicon Era.
If you missed George’s previous issues, or would like to read them again, you can access them here: Part I, Part II, Part III (these, along with all other Spotlights, will also soon be hosted inside our private members’ area).
Finally, if you’d like more from George Gilder, including all his recommendations for capitalizing on the most disruptive technologies of the future – make sure you check out his advisory here.
One of his biggest bets right now is on what he says is “the only computer that can power the next generation of AI.”
At the climax of the Silicon Era, two trends are decisive for investors: the centralization of information processing and the supersizing of the leading semiconductor firms. Yet both trends incorporate contradictions that will make for their ultimate reversal.
The first trend is toward supersizing the hardware makers, especially the foundries, forced by a technology challenge that makes economies of scale painfully advantageous. The industry pursues increasingly ingenious ways to extend Moore’s Law, understood as the periodic doubling of computational power on a single chip.
Today, this is pursued not only by the traditional doubling of the number of circuits per mm2. Also crucial are architectural innovations such as 2.5D and 3D chips. Both approaches—shrinking circuit sizes and architectural innovation—are now so difficult and expensive to execute that they favor the largest producers.
Ultimately, the trend toward giantism will be terminated by wafer-scale graphene electronics, sending the industry back to its planar roots as circuits fire hundreds of times faster while generating less heat. The need for fancy 3D architectures will recede. Manufacturing will go through a phase of simplifying. Even design costs, increasingly complicated to accommodate growing manufacturing challenges, should ease.
When? Graphene electronics is unlikely to appear sooner than five years from now, but it could be a decade. When it comes, it will likely come from China. In the meantime, there is money to be made by the giants.
Today, we look at how the current successes of Taiwan Semiconductor (TSM) plays out against this backdrop.
The Great Data Delusion
The other great centralizing trend is the exponential shift of computation to ever more hyperscale data centers. This trend will self-terminate not because of a new material like graphene—which would ease the great data center energy crisis—nor any other exogenous event, but because data centralization has come to undermine its own goal.
Up until fiber optics, computation was distributed and local because the computer always ran faster than the network, then mostly 3 kilohertz analog voice telephone lines moving data at 64 kilobits a second. Computers, by contrast, operated in megahertz, millions of cycles a second.
Then in 1993, from a workbench at Sun Microsystems in Silicon Valley in Los Altos, California, Eric Schmidt, soon to ascend to chief technology officer (CTO), divulged the apothegm that I would dub Schmidt’s law: “When the network runs faster than the backplane of the computer, the computer hollows out and spreads across the network.”
Swiftly, first mid-long-term memory storage, and then “Software as a Service,” did move to the data centers. Big Data, driven by the notion that future customer choices could be predicted from exabytes of past choices, accelerated the trend. Generative AI is accelerating the centralizing trend exponentially.
Nvidia CEO Jensen Huang enthuses about a trillion dollar rebuild of existing centers that will become a source of unprecedented productivity.
NVIDIA’s acceleration of computing, he says
“Enabled …the beginning of a new industry where AI-dedicated data centers process massive raw data to refine it into digital intelligence… Generative AI has kicked off a whole new investment cycle to build the next trillion dollars of infrastructure of AI-generation factories… [This] will drive a doubling of the world’s data center infrastructure… and will represent an annual market opportunity in the hundreds of billions.”
I believe this vision will disintegrate as it becomes clear that hyperscale data, the billions and trillions of instances used to train “generative AI” has become not a path forward but a stumbling block.
The very ability to amass and process all that data has proved a fatal temptation. Luring us on like the Tree of Knowledge in the Garden of Eden has been the illusion that by stuffing all past answers to all past questions into a single machine it would become as a god, revealing the right answer to every new question. The founders of generative AI ate the apple. East of Eden lies not clarity but confusion and chaos.
In the spring of 2017, eight Google researchers released a paper that launched the new era of AI. Beginning “by dumping out all the then-entrenched neural architectures” used at Google, they announced a “transformer” model that calculated responses almost instantly in parallel on vast databases.
These eight Googlers set forth their new vision in the title of their paper: “Attention is All You Need.”
Who needs logic? We got data!
The authors dispensed with Google’s prevailing search algorithm for a scaled-up system that paid mathematical “attention” to the entire context of the inquiry. But then the authors made their amazing discovery: “attention is all you need.” Once they had enough global context, they could dispense with much of Google’s previous mazes of intricate “convolutional” logic and algorithmic processing. Rather than seeking the most logical next step, they could rely on increasing benefits of massive scale in the database and parallel processing in the data center for global insight.
In the words of the paper, they scaled up, moving from induction, a logical process deriving rules from immediate evidence to transduction: paying attention to patterns in masses of data that include all possible associations and affiliations of a term. Scale of data trumps ingenious logic. By scale they weren’t kidding. They meant trillions (1012), or even exponentially more datapoints or parameters measured in exabytes (1018) and zettabytes (1021). Step-by-step logic would give way to “multi-headed attention” and massively parallel multiplications of vast data matrices in giant data centers.
The new scheme starts with pattern recognition code to “transform” masses of Internet and library data into a huge mathematical map of statistical associations, affiliations, and probabilities. Recognizing that everything is connected to everything else in different levels of dependency and influence, transformers can turn text, images, video and audio, math and science, all expressed in numerical arrays, into an integrated map of relationships.
By changing the weight of links among the nodes of numbers according to the results of prompts and queries, transformers constantly improve their model. Answers become more subtle, detailed, accurate and faster. The “weights” of the links between the datapoints or “tokens” are weakened or strengthened with each wrong or right answer, so responses improve with every use. The team saw no signs that improvements in performance taper off as the models grow.
The bigger the data center, the better the results.
Today, seven years later, nearly everyone in AI is contemplating “transformer models” with trillions in parameters, which Nvidia plans to transform into trillions of dollars.
With the thoughts I’d be thinkin’
With systems that can process in seconds more text or images than a human could consume in a lifetime, awed researchers imagined that the system was spontaneously beginning to think like a human—or at least a computer scientist—even showing glints of “consciousness.” Deeming the group to have mastered the mystery of mind, Sundar Pichai, Google’s CEO, called the discovery by the Eight “more important than electricity or fire.”
You better trust, ‘cause we don’t verify
What it really is, is an enormous new search engine that conceals its sources, refusing verification. As already demonstrated hilariously by pundits as diverse as Matt Taibbi and Ann Coulter, it is as open to manipulation as any centralized system. It’s an ingenious way to synthesize and summarize, and even plagiarize without leaving tracks.
Best of all, it is never wrong! Because it knows right is an average, a probabilistic pattern matching mix that dependably tells you what used to be the consensus view.
Seeking desperately to evade charges of tedium and tendentiousness, newer versions simulate creativity by injections of randomness. Creativity, however, resembles randomness only in its statistical signature. If creativity were randomness, Michelangelo could have saved himself the agony and painted the Sistine Chapel ceiling as ecstatically fast as Jackson Pollock.
Neither James Watt nor Charles Babbage nor Thomas Edison nor even Google Founders Larry Page and Sergei Brin were random number generators. They sought not to average the past but to overthrow it by pursuing new, and right answers by falsifiable experiments.
The very principle of experimentation is to identify difference, to isolate the novel, the variable that matters. Controlled experiment starts with a model of the world: smallpox spreads almost unstoppably. It observes an anomaly, a surprise discovered by accident or trial and error: milk maids don’t get smallpox. The searcher hypothesizes a source of the anomaly, infection with cowpox, isolates the variable and tests it.
Experiments work not by averaging the past but by making falsifiable predictions of how a change—a variable— will alter the future.
A useful AI would produce falsifiable predictions about the impact of a change in the world and do so with the millionths of the energy a human brain uses compared to a supercomputer.
It’s coming.
A less artificial intelligence
As we noted recently, perhaps the most interesting herald of this future AI is to be found in VERSES AI (VRSSF) and its Genius™ platform. The paradigm shift Verses proposes is grounded in the principles of Active Inference, as developed by neuroscientist Karl Friston, one of the world’s most cited scientists, and inspired by the efficiency of the human brain.
Driving active inference is Friston’s Free Energy Principle (FEP)—a way of understanding how biological systems, including the human brain, balance the need to maintain order and yet adapt to their changing environments. FEP incorporates staggering mathematics, but the core idea is comprehensible. Living organisms try to minimize the difference between the sensory inputs they expect based on internal models developed in experience—the model of the world before the variable is introduced—and the actual, contrasting sensory inputs they encounter in the wild. This difference is termed “free energy.” By minimizing free energy—adjusting their internal models to the unexpected inputs—organisms reduce surprise, maintaining their internal order. And they do this with remarkably little exertion.
The AIs of the “transformer” are not only too expensive, but power hungry, imitative, readily infected by biases and lacking transparency. Once trained, they become rigid and dogmatic. With their stark divisions between their training phase—when they get “educated”—and their inference phase when they apply their learning, the models are not unlike a Harvard grad who never reads a book after scoring the sheepskin.
The contrasting goal of Verses is to build AI “agents” that “learn how to learn” by efficiently seeking out and incorporating relevant data. Since that data is specified and relatively compact, the result is a decision-making process comprehensible to humans. We know why the agent reaches a conclusion. The variable is visible, the answers falsifiable.
Tom Landry would love it
Active inference is a bit like a defensive alignment that bends rather than breaks, so as to adapt to surprise. A player in a “bendable” formation might rotate into position as the play develops. Yes, he was “surprised” by the offense, but he was positioned to absorb the surprise. He was ready to be surprised. Active inference is the difference between thinking on your feet and being caught flat-footed.
In statistics, this process is called identifying a Markov blanket, which helps to extract useful features. Humans call this “focus” or knowing what matters. We evaluate events against our existing models to determine what is important to make new inferences.
An AI for the spatial web and the phygital world
At some point it will become clear that “transformer AI,” like the woke Ivy League, not only costs too much but makes its users dumber. When we reach that point, a somewhat less artificial intelligence will take hold at the edge of the network, even as the edge becomes the spatial web encompassing a ‘phygital’ world. Data centers will continue to be a convenience. Nvidia will continue to make money. But the super-mega-maxima-hyperscaling moment will have passed.
Why Does TSM Make so Much Money?
As a manufacturing facility rather than a design house, one might expect TSM to reap lower margins compared to its IP-driven customers such as NVDA, QCOM, AMD, or AAPL. Yet on operating margins, TSM routinely outperforms those companies. Over the five years ending in December 2023, TSM’s average operating margin of almost 42% outstrips Apple (28%) QCOM (26%), AMD (9%) and even NVDA (32%), though NVDA in its most recent 12 months hit 54%.
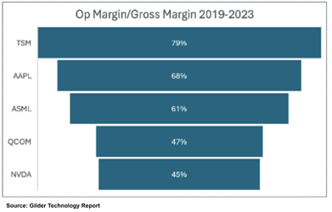
TSM holds on to its advantage even all the way down to the net income line (after tax). Over the previous five years, NVDA, QCOM, and AAPL all averaged in the mid-20s for percent of revenue that hit the bottom line.
Meanwhile, TSM’s net margin for the period averaged 38% and never fell below 32%, an extraordinary performance.
What’s going on? Outsourcing.
“Wait a minute!” we hear you objecting. “TSM is the company all the design firms outsource to! What is it that TSM is outsourcing?”
Its R&D.
TSM’s operating margins are bolstered by its relatively low research and development costs compared to both its customers and its vendors. That’s in part because both its customers and its vendors do much of TSM’s R&D for it.
To get to the bottom of this, we compared gross margin to operating margins for 2019-2023 for five companies, TSM itself, three of its largest customers—AAPL, QCOM, and NVDA—and one large vendor to TSM, ASML—to see which of the five companies retained the greatest percentage of gross profits after operating expenses.
The graph shows the results. A big reason TSM’s operating margins beat all the others is that TSM holds on to a greater percentage of its revenue between the gross margin line and the operating margin line.
Between the gross and operating lines come operating expenses, the two most significant being SG&A (Sell- ing, General, and Administrative) and R&D. For four of the five companies, R&D dwarfs SG&A. AAPL is the slight exception. It does have above average R&D costs compared to most American firms, but its SG&A expenses often run neck and neck with R&D. It’s a consumer products company with a big sales force, retail stores, and an advertising budget.
Next, we looked at how much of the erosion between the gross margin line and the operating margin line was down to R&D. We divided gross profit into R&D and then averaged the result over the five years to get the percentage spent on research and development.
This is what we found:
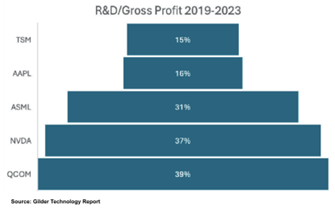
Most of the gap between gross and operating profit for these companies is explained by R&D spending. TSM and AAPL spend less than half as much on R&D as a percentage of gross profit as NVDA and QCOM and just about half as much as ASML.
This is not an argument against high R&D spending by innovative companies. Neither ASML, NVDA, nor QCOM would exist had they not for years poured more than 100% of revenue into R&D. All three need to keep investing in innovation to hold their positions in the industry.
TSM is also an innovator, not only the world’s biggest semiconductor foundry but the best. Yet much of its innovation is outsourced. When TSM pays ASML more than $350 million for a high-NA, extreme ultraviolet lithography machine to etch nano-scale circuits for a chip, it is paying largely for the research and development of the machine.
TSM has “supply partners” across almost 20 industry sectors. We picked ASML because it is one of the most important and is far and away the most innovative large company in its field. Many other wafer fab equipment (WFE) companies spend a smaller proportion of gross profit on R&D than does ASML, but most spend significantly more than TSM itself.
As for TSM’s customers, they must design products to the manufacturing processes TSM provides. This is very much a two-way street, with TSM designing processes its customers need. The breadth and depth of cooperation between the design houses and the foundries is probably greater today than 15 years ago and is all the more needed the more challenging the process. Once a process is established, however, usually multiple customers can avail themselves of it with modest modifications. The designing to manufacturing process shifts at least some R&D costs from foundry to designer, though pinning down a number is practically impossible.
For a rough indicator, compare R&D spending at Intel, which both designs and manufactures most of its chips, in a tight merger between device design and process design. In most years Intel’s R&D as a percentage of gross profit is in the low 30s, comparable to ASML’s. (Recently that number has been as high as 69%, as revenues have slipped and CEO Pat Gelsinger has boosted R&D spending by almost 20%.)
There is, as the man said, no such thing as a free lunch. Though TSM’s R&D spending may be small relative to its customers, its capital expenditures for plant and equipment are massively larger. In each of the last three years, TSM has invested more than $30 billion in such assets, more than 90% of its gross profit each year and more than 100% of gross profit in 2021. TSM makes an accounting profit only because of massive depreciation allowances, averaging more than $15 billion a year for those three years. NVDA, by contrast, spent about $1.3 billion a year on plant and equipment during the same period.
R&D spending is treated as an expense and deducted from income. Investments in plant and equipment are capitalized. They show up on the balance sheet and the cash flow statement but not on the income statement except gradually as depreciation.
This boosts TSM’s operating and net income lines compared to here.
Yet the advantage to TSM is not all accounting smoke and mirrors. TSM’s investments have staying power. The U.S. depreciation schedule for wafer fab equipment is five years. Some cutting-edge equipment becomes legacy equipment in less than five years. Yet, TSM makes good money on “legacy” processes for which it can use that older equipment. Even the amazing ASML photolithography machines are good for several generations of processes. The biggest Chinese fab, SMIC, may have figured out a way to make chips in “7nm” mode with the same ASML equipment it used for “14nm.”
A fair valuation of TSM would have to account for the $100 billion in hard assets on its balance sheet.
In sum, TSM has a brilliant business model, anchored in ongoing realities of the industry. Its market share and gross and operating margins have all been on the rise over the past five years we have examined. The company is secure enough in its position that it is raising prices. Barriers to entry for competitors are rising, including the rapidly climbing costs of building a new fab.
TSM’s extraordinary operating and net margins are not anomalies and we believe the company is still undervalued despite the stock’s exceptional recent run.
Ultimately, the answer is graphene and a complete disruption of the current industry.
In the meantime, there is money to be made in the climax of the silicon age and most of it will be made by the giants, just before the extinction event.
Until Then!
George Gilder
Editor, Gilder’s Technology Report & Gilder’s Moonshots
P.S. If you’d like more from George Gilder, including all his recommendations for capitalizing on the most disruptive technologies of the future – make sure you check out his advisory here.